Data cleaning on SAP data extracts in .txt format with Regex and Python
Introduction
During one of our recent projects involving the procure to pay process, our team encountered SAP raw data extracted from the system in .txt format which proved to be difficult to clean using traditional methods like readlines() or split() by delimiters due to some inherent data inconsistencies.
Regex matching proved to be helpful for such scenarios to clean the data.
Common SAP tables in Procure to Pay process
First, lets go through what are common data tables extracted from SAP as part of the Procure to Pay process.
Accounting Related Tables
- BKPF: Accounting Document Header
- BSAK: Accounting: Secondary Index for Vendors
- BSEG: Accounting Document Segment
Purchase Order related Tables
- EKKO: Purchasing Document Header
- EKPO: Purchasing Document Item
- EKBE: History per Purchasing Document
- EKKN: Account Assignment in Purchasing Document
Material Tables
- MAKT: Material Descriptions
There are various websites which provide additional information about the SAP tables.
- https://www.se80.co.uk/training-education/sap-tables/
- https://www.tcodesearch.com/sap-tables/detail?id=BSEG (Might need to enter through changing the id in URL without requiring premium membership)
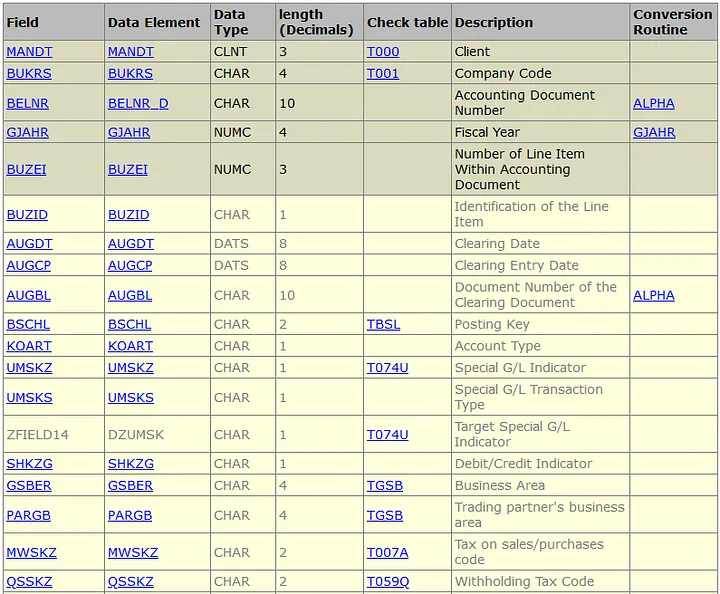
Format of SAP data extract in .txt file
For our project, the output SAP data extracts is in a .txt format and with the typical structure as shown below:
- The column header details starts at line 4
- The width of each column is consistent between the column headers and the data for each file extracted
- Actual data content starts at line 5 till the end
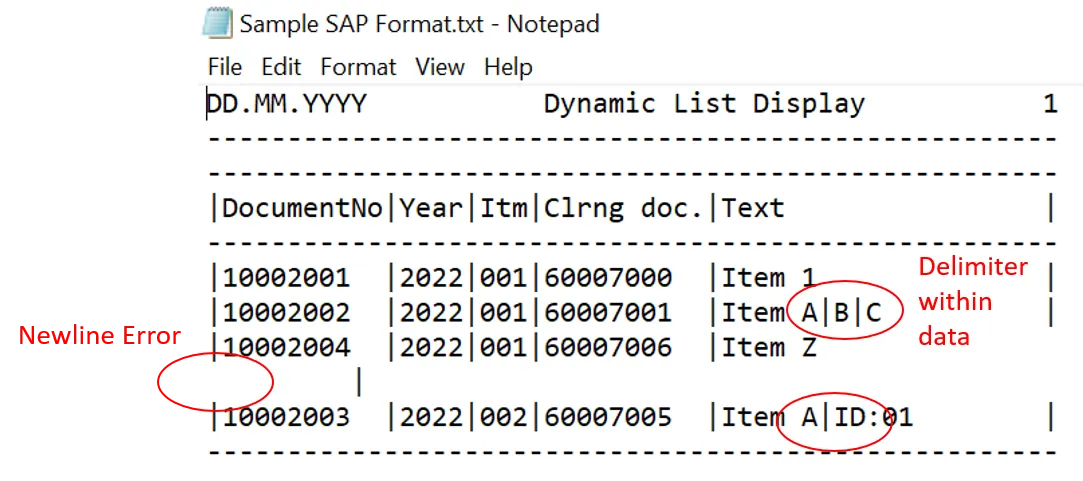
The sample SAP data in txt format and Jupyter Notebook can be found on GitHub: https://github.com/ZS-Weng/Data_Engineering/tree/main/Data_Cleaning
The two major data discrepancies encountered are:
- Newline character inserted in some of the fields
- Pipe (|) delimiters found within the actual data
Full Code and Output
The full working code for the data cleaning is as shown below:
import pandas as pd
import re
# Read File
with open("Sample SAP Format.txt", encoding="utf-8") as f:
content_raw = f.read()
# Clean extra newline characters
new_line_pattern = re.compile("([^1|-])[\n](.)|(.)[\n]([^|-])")
content_cleaned_newline = new_line_pattern.sub(r"\1 \2", content_raw)
content_split_line = content_cleaned_newline.split("\n")
# Clean the rest of content
# Extract Header and Row Pattern
header_string = content_split_line[3]
column_header = [token.strip() for token in header_string.split("|")][1:-1]
list_column_width = [
"(.{" + str(len(column)) + "})" for column in header_string.split("|")
][1:-1]
column_string_pattern = "[|]" + "[|]".join(list_column_width) + "[|]"
#Extract Data Body
column_pattern = re.compile(column_string_pattern)
cleaned_content = [
[token.strip() for token in column_pattern.match(row).groups()]
for row in content_split_line[5:-2]
]
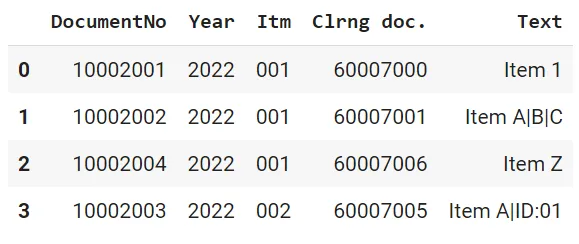
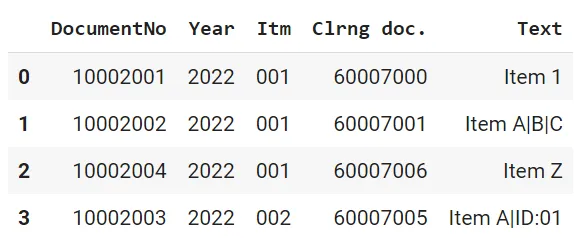
df_clean = pd.DataFrame(cleaned_content, columns=column_header)Final pandas data frame output:
Detailed Walk-through of the codes
Cleaning of newline character prior to splitting lines
In order to clean the (newline) characters which are not valid, we first use the read() instead of readline() method as the readline() method will split the lines by the character automatically.
with open("Sample SAP Format.txt", encoding="utf-8") as f:
content_raw = f.read()Next, we use the Regex pattern ([1|-])[\n](.)|(.)[\n]([^|-]) to find and the invalid characters. The pattern basically detects newline that do not start with the characters 1 , | or - and do not end with the characters | or -.
For the invalid newline characters found, we replace them with a space using the .sub() method.
new_line_pattern = re.compile("([^1|-])[\n](.)|(.)[\n([^|-])")
content_cleaned_newline = new_line_pattern.sub(r"\1 \2",content_raw)
content_split_line = content_cleaned_newline.split("\n")Output after cleaning and splitting lines:
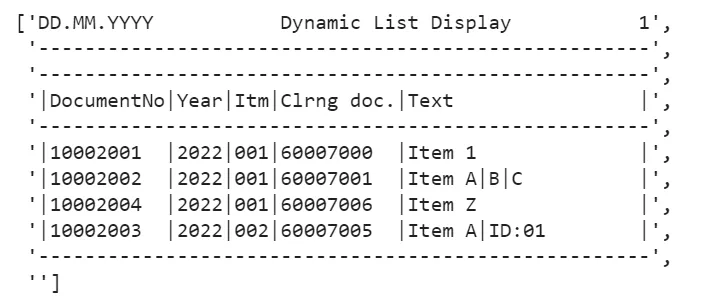
Data Cleaning Steps for Individual Line Based on the above, we can see that the data we are interested in is the column header (4th line) and the rest of the data content (6th to 2nd last lines).
We will first split the column by the pipe “|” delimiter and getting the columns width to create the Regex matching string pattern.
header_string = content_split_line[3]
column_header = [token.strip() for token in header_string.split("|")][1:-1]
list_column_width = ["(.{" + str(len(column)) + "})" for column in header_string.split("|")][1:-1]
column_string_pattern = "[|]" + "[|]".join(list_column_width) + "[|]"The column_string_pattern to match that is generated for the sample data will be as follows:
[|](.{10})[|](.{4})[|](.{3})[|](.{10})[|](.{20})[|]This column pattern matching pattern is dynamically generated and will be unique for each of the data extract file even for the same tables as the width is adjusted during data extract according to the content.
We will then use the matching pattern to extract the rest of the data (6th to 2nd last line) with re.match().groups() instead of using the str.split() method.
column_pattern = re.compile(column_string_pattern)
cleaned_content = [[token.strip() for token in column_pattern.match(row).groups()] for row in content_split_line[5:-2]]The output after content splitting:

Here we can see that the extra delimiters e.g. ‘Item A|B|C’ does not affect the content splitting .
Finally, we combine the cleaned header columns and data into a pandas data frame.
df_clean = pd.DataFrame(cleaned_content, columns=column_header)Final pandas Data Frame output:
Useful Learning Resource for Python and Regex
When I was starting out, I found the book Automate the Boring Stuff with Python by Al Sweigart one of the best resources to learning about Python and Regex with many practical examples.
There is a free access option to the book on his website: https://automatetheboringstuff.com/ and this is the link to the specific chapter on Regex which formed the foundation on some of the implementation: https://automatetheboringstuff.com/2e/chapter7/
Thanks for reading and hope the information was useful in some way!